Insights
The Weakeast Link in a Data Centre Resilience Isn't the Equipment
The Hidden Cause of Most Data Centre Failures
Most major data centre outages are initially suspected as equipment failures. Yet the most disruptive incidents occur when no equipment has failed. How can a facility fail if nothing fails? This occurs when otherwise reliable systems fail to interact in the manner the facility was intended to operate.
Modern data centres contain hundreds of interconnected systems, devices, software platforms, control schemes, protection systems, and operating procedures. As facilities become more resilient and increasingly automated, the number of interfaces between those systems continues to grow. The challenge is that reliability is no longer determined solely by the performance of individual assets. It is determined by how effectively those assets behave together.
In many cases, the greatest threat to operational resilience is not a failure of equipment. It is a failure of the interfaces that govern how equipment communicates, coordinates, and responds under abnormal conditions.
2. The Ownership Gap
One of the most overlooked risks in modern data centre projects is that nobody truly owns the interfaces.
The electrical MV/LV switchgear vendor owns the MV & LV switchgear.
The UPS /ASTS Vendor owns the UPS & ASTS
The specialist controls contractor owns the BMS.
The switchgear vendor owns the protection settings.
The automation specialist owns the PLC logic /EPMS.
The operations team owns the procedures.
Each party delivers their respective scope.
Yet the interaction between those systems often sits between contractual boundaries.
This creates an ownership gap.
The risk does not lie within the individual systems themselves. It lies in the assumptions each system makes about how the others will behave. Commissioning leadership exists to close that gap. Without a coordinated review of these interfaces, each vendor can successfully deliver its scope while the integrated facility still exhibits unintended behaviour.
3. Why Interfaces Matter
Most significant operational incidents do not begin with a catastrophic equipment failure.
More commonly, a fault, alarm, control signal, software action, protection operation, or human intervention initiates an unexpected sequence of events across multiple systems.
In these situations:
Equipment frequently operates exactly as designed.
Protection systems perform correctly.
Control systems execute programmed logic.
Operators follow approved procedures.
Yet the overall facility response is not what was intended.
The consequences can include:
Loss of redundancy
Unplanned power transfers
Loss of critical services
Reduced fault tolerance
Cascading failures
Service interruption
The facility fails not because a component failed, but because the combined response of multiple systems produced an unintended outcome.
What Constitutes an Interface?
Many engineers associate interfaces primarily with software integration or BMS communications. In principle, interfaces exist wherever information, commands, status signals, control actions, or operational decisions pass between systems or people.
Examples include:
Physical Interfaces
Hardwired control signals
Protection trip circuits
Communication networks
Instrumentation and sensors
Controls and Logic Interfaces
UPS and ASTS transfer logic
Load shedding schemes
Generator power management systems
Automatic restoration sequences
System-to-System Interfaces
BMS and cooling plant controls
Fire systems and HVAC systems
Generator controls and electrical distribution systems
EPMS and operational monitoring platforms
Human Interfaces
SCADA systems
BMS workstations
Operator actions
Alarm management processes
Operational Interfaces
Switching procedures
Emergency operating procedures
Maintenance activities
Incident response processes
Every interface has the potential to influence facility behaviour.
4. Why Interface Failures Occur
Interface failures rarely result from a single defect.
They typically emerge from multiple small assumptions that remain hidden until an abnormal operating condition exposes them.
Common causes include:
Design Deficiencies
Incomplete Sequences of Operation
Contradictory control philosophies
Undefined failure scenarios
Missing recovery sequences
Implementation Issues
Incorrect programming
Alarm routing errors
Point mapping mistakes
Protection setting errors
Integration Issues
Vendor assumptions
Communication failures
Timing mismatches
Incomplete end-to-end testing
Operational Issues
Configuration drift
Uncontrolled modifications
Weak change management
Loss of operational knowledge
The common characteristic is that these defects often remain invisible during normal operation.
They only become apparent when the facility experiences a disturbance.
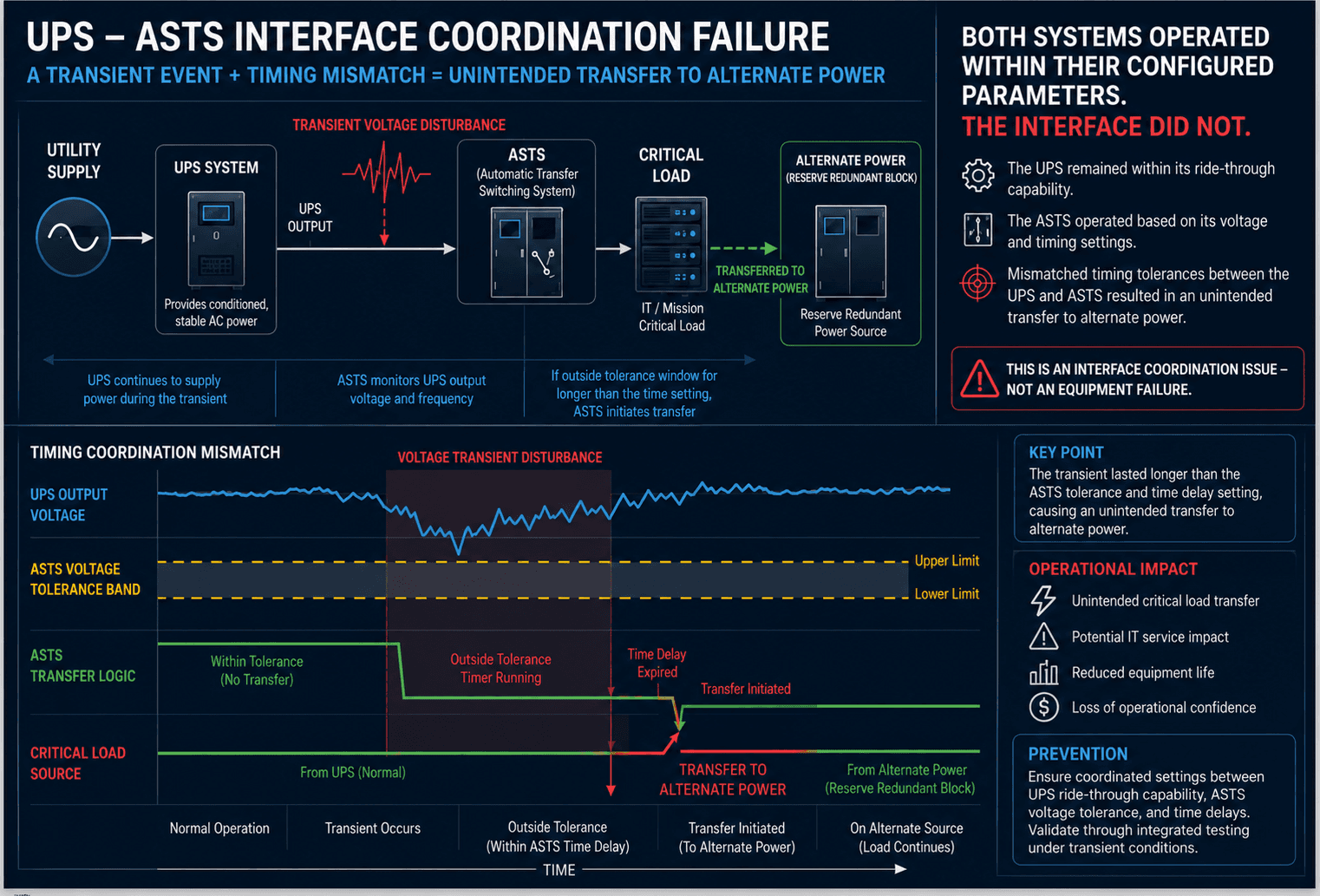
5. A Real Example: When Correctly Functioning Systems Produced the Wrong Outcome
During ASTS functional performance testing on a Tier III data centre, the facility had been operating under full load on utility power for approximately one hour. As part of the test sequence, the facility power was transferred from utility to generator. During the transfer, the ASTS unexpectedly transferred the critical load from the preferred UPS source to the Reserve Redundant Power Block. The immediate concern was that a fault had occurred within the preferred power path. Investigation quickly revealed a more interesting finding: no equipment had failed.
The facility was a 3 MW Tier III data centre configured with dual utility incomers and 3 active N+1 UPS Power Blocks supported by a dedicated Reserve Redundant Power Block. The ASTS, configured to transfer between the preferred UPS source and the Reserve Redundant Power Block when source quality or availability fell outside configured acceptance criteria, supplied the critical loads.
The investigation revealed that the transfer from utility to generator operation introduced a transient voltage disturbance on the preferred UPS source. The UPS remained online throughout the event and continued supplying conditioned power to the critical load within its designed ride-through capability. However, the disturbance exceeded the voltage acceptance criteria and timing window configured within the ASTS. As a result, the ASTS interpreted the preferred source as degraded and transferred the load to the alternate Reserve Redundant Power Block.
At first glance, this appeared to be an ASTS problem. It was not.
Further investigation revealed that neither the UPS nor the ASTS had malfunctioned.
Both systems performed exactly as configured.
The root cause was a coordination mismatch between:
UPS ride-through characteristics
ASTS source acceptance criteria
ASTS transfer timing settings
Perhaps most significantly, both systems were supplied by the same vendor. This demonstrated that common ownership of equipment does not automatically guarantee coordinated system behaviour. The disturbance should have remained transparent to the critical load. Instead, a mismatch between the UPS ride-through characteristics and the ASTS source acceptance and transfer timing criteria resulted in an unnecessary transfer to the Reserve Redundant Power Block refer to Figure 1. UPS – ASTS Coordination Failure.
No equipment failed and no control system malfunctioned. The event exposed a deficiency in the coordination of the interface between two otherwise correctly functioning systems.
6. The Commissioning Leadership Lesson
The most important lesson from this event is that successful commissioning of individual systems does not guarantee successful operation of the integrated facility.
Traditional commissioning often focuses on verifying that systems operate correctly in isolation.
Modern mission-critical facilities require verification that systems operate correctly together.
This demands:
Interface coordination reviews
Cross-system control philosophy validation
Sequence of Operation verification
Protection coordination reviews
Timing and tolerance alignment
Integrated Systems Testing under realistic operating conditions
Most importantly, it requires leadership that understands the facility as a complete system rather than a collection of individual assets. The commissioning leader's role is not simply to verify equipment. It is to challenge assumptions, expose hidden dependencies, and ensure that independent systems behave as a single coordinated infrastructure platform.
7. Conclusion
Data centre resilience is often discussed in terms of redundancy, concurrent maintainability, fault tolerance, and equipment reliability. These remain important.
However, as facilities become increasingly automated and interconnected, the greatest operational risks are often found elsewhere. They exist in the controls, logic, communications, timing windows, operational procedures, and assumptions that govern how systems interact.
No amount of factory testing would have revealed this issue. No amount of standalone UPS testing would have revealed this issue. No amount of standalone ASTS testing would have revealed this issue. The defect only became visible when the systems were tested together under realistic operating conditions. This makes the case for integrated systems testing (IST) compelling.
Mission-critical infrastructure rarely fails because a single component stops working.
More often, it fails because multiple components work exactly as designed but produce an unintended outcome when combined. The weakest link is not usually the equipment. It is the unmanaged interface between otherwise reliable systems. That is why commissioning leadership, technical assurance, and integrated systems testing remain essential to achieving true operational resilience.
Modern commissioning is no longer simply about proving that equipment works. It is about demonstrating that interconnected systems behave as intended when subjected to realistic operating conditions.
In increasingly automated mission-critical facilities, mission-critical facilities do not fail as individual systems; they fail as integrated systems. Consequently, modern commissioning must focus not only on proving that equipment works, but on demonstrating that the facility behaves as intended.
Need Independent Technical Assurance?
TEO Consulting Engineers provides:
Commissioning Authority (CxA)
Technical Assurance
Reliability Assurance
Integrated Systems Testing
Owner's Engineering Advisory
Submit a Consultation and we'll respond within one working day.